Análisis de colaboración en comunidades por medio de análisis de redes sociales
Análisis de redes sociales - elementos básicos

Análisis de redes sociales - elementos básicos

Análisis de redes sociales - elementos básicos

Análisis de redes sociales - elementos básicos

Análisis de redes sociales - medidas básicas

Análisis de redes sociales - medidas básicas

Análisis de redes sociales - medidas básicas

Análisis de redes sociales - medidas básicas

Análisis de redes sociales - medidas básicas

¿Por qué analizar nuestra comunidad de práctica?

Participar de rOpenSci

Escribir para el blog

Revisar un paquete

Mantener un paquete

Hablar en una Comm Call

Convertirte en campeón/a

Ser anfitrión de un encuentro
Participación en una red
N:autor. E:coautoría
N:autor, editar, revisar. E:peer-review
N:desarrollo. E:co desarrollo.
N:disertante. E:panel, coorganización
N:tutores, mentoreade. E:mentorías
N:participantes. E: coorganización, asistentes
Datos para la red
Webpage
GitHub, base de datos
GitHub,r-universe
Webpage
Webpage, base de datos
Webpage
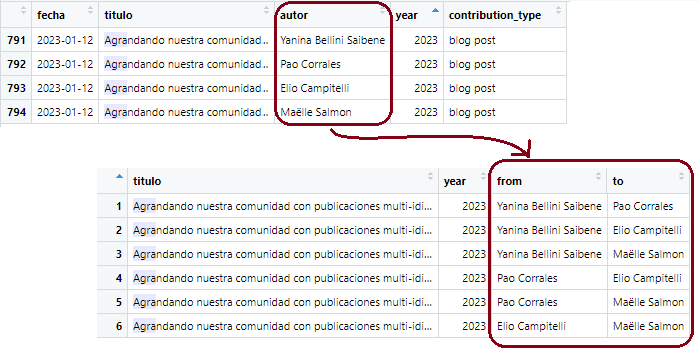
Un ejemplo con el blog

Veamos un ejemplo
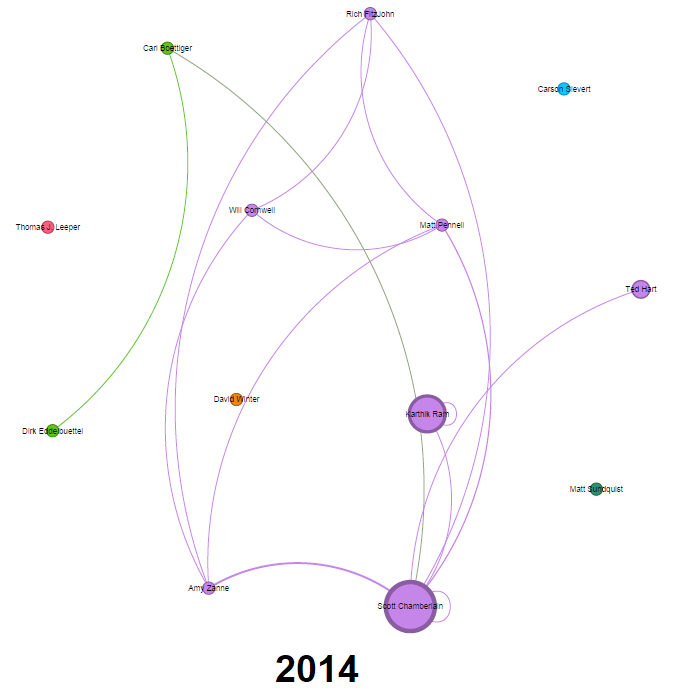
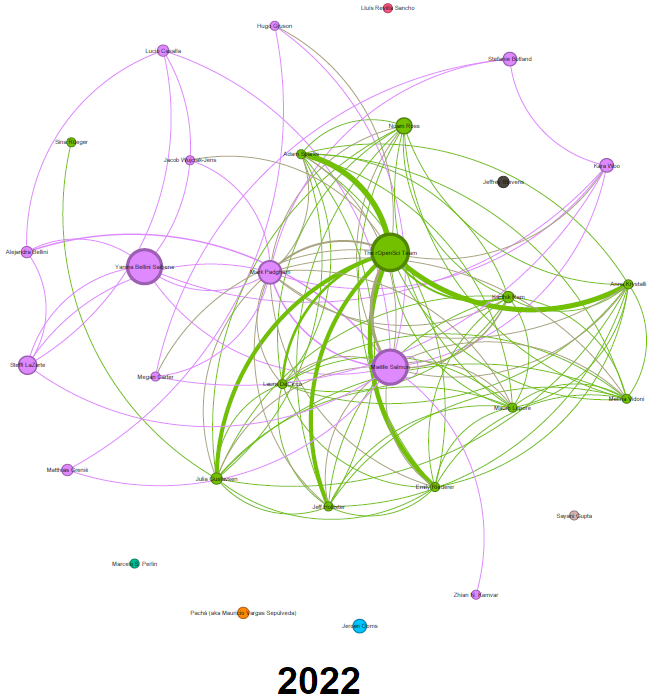
Red completa de autores de blog 2013-2023

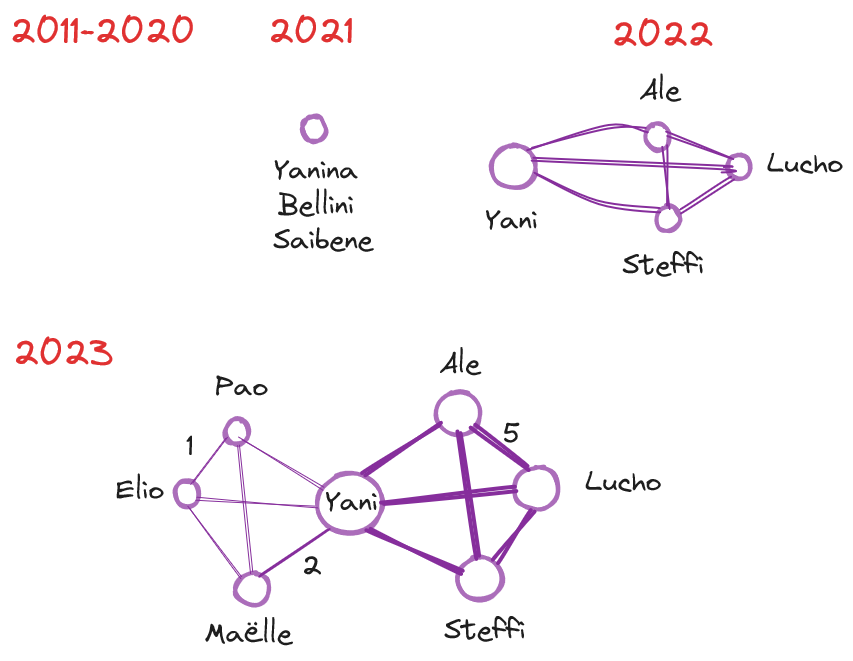
Podemos analizarlo anualmente
O por idioma - artículos en español
O por país
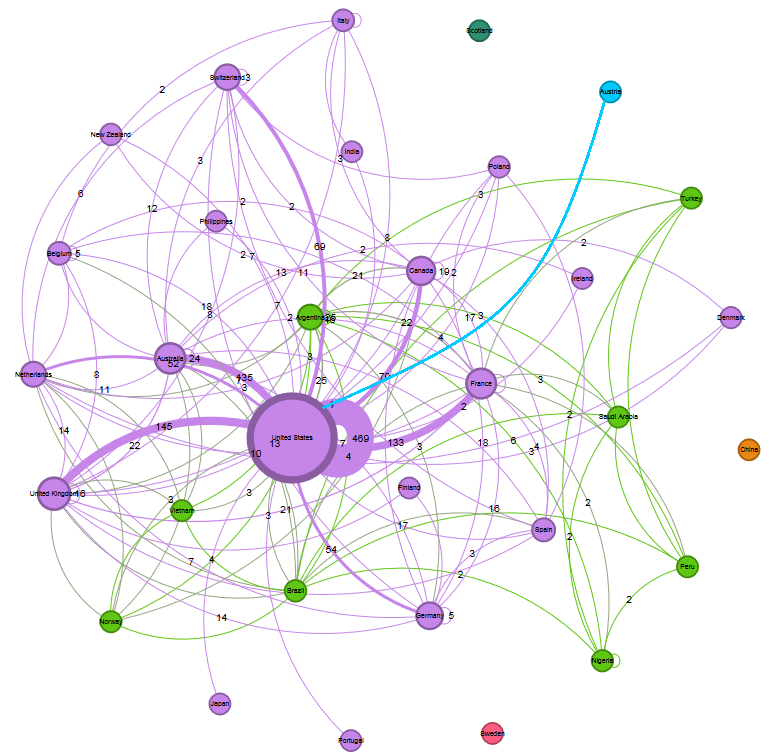
¿Y si queres hacer lo mismo para tu comunidad?

¡Gracias, Thank you, Obrigada!
- GitHub: https://github.com/yabellini/rOpenSciLatinR2023
- Las figuras son adaptaciones de mi hijo pequeño y mias de imágenes por Freepik sobre el set hand drawn style stickman
- Usamos R, gephy, excalidraw y quarto para construir esta charla.
- Gracias al equipo de rOpenSci Staff, Elio, Ale, Sandro y a mi Club de conversación en Inglés por su feedback.

